Hi there, just writing with a (hopefully) straightforward question about weighting in the 2013 ACS.
I have 2 ways that I’ve tried to estimate the proportion of households that live near good schools, according to a variable I’ve created with data I merged into the ACS at the PUMA level, captured in the variable “deprived_of_good_ed,” which is either 0 or 1. 1 means “deprived”; 0 means “not deprived, there are decent schools in the PUMA.” This variable is a little goofy, but please humor me, this question isn’t about goofy measurement of access to good schools.
Anyhow, I’m trying to tab this at the household level, for households with heads between 25 and 54, by race.
So: here’s the first way I’ve tried to do this.
tab deprived_of_good_ed if relate==1 & (age >24 & age <55) & race==2 [w=hhwt]
tab deprived_of_good_ed if relate==1 & (age >24 & age <55) & race==1 [w=hhwt]
It creates an output that looks like “output 1,” attached. It tabs black households (race==2), then white households (race==1)

Is that an acceptable way to estimate these proportions?
If not, is the way below acceptable:
gen target_group = 0
replace target_group = 1 if relate==1 & (age >24 & age <55)
svyset serial [pweight=hhwt], vce(linearized)
svy, subpop(target_group): mean deprived_of_good_ed, over(race)
This creates an output that looks like “output 2,” attached.
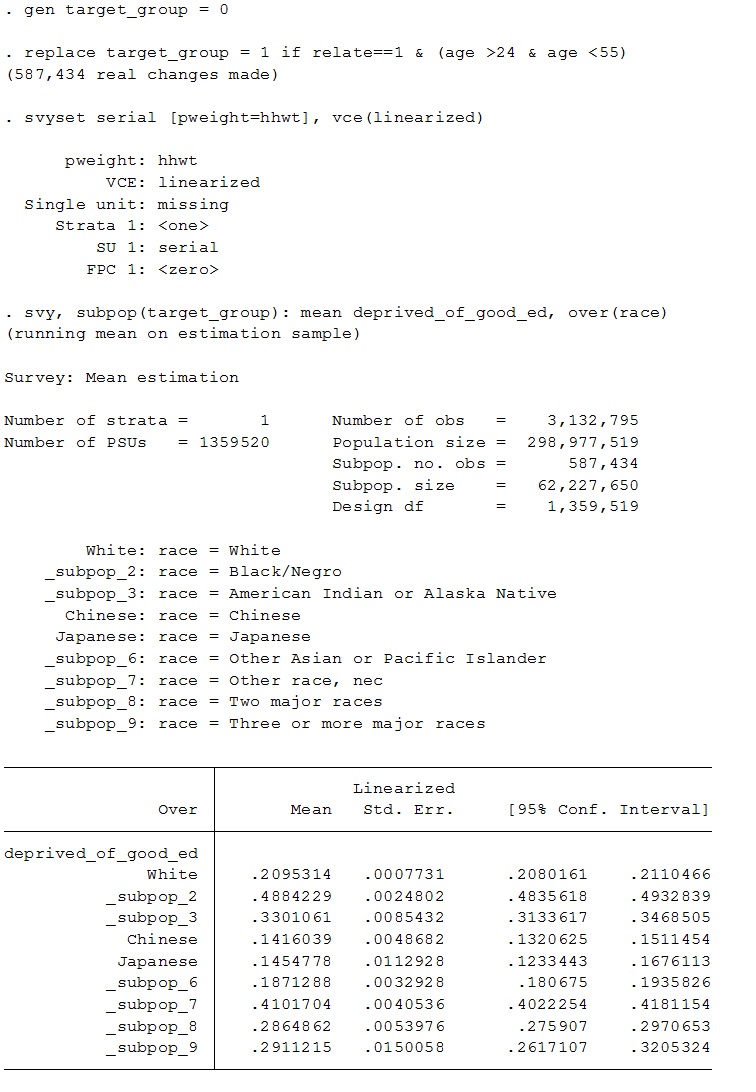
These estimates, I notice, are somewhat different. Eager to hear which are correct–which method above is correct–or if I need to do something different entirely.
Thanks as always!